A la dècada dels vuitanta de segle passat el genetista italià Luigi Luca Cavalli-Sforza va començar la publicació d’una sèrie de treballs que descobrien l’existència de similituds entre la diversificació i distribució territorial de grups genètics i de famílies lingüístiques.
Des dels anys cinquanta Cavalli-Sforza, format en genètica bacteriana, s’havia interessat per la genètica de poblacions, mogut pel propòsit de reconstruir la història de dispersió de les poblacions humanes. Al llarg dels temps, els humans s’han organitzat en grups que comparteixen tradicions culturals, característiques lingüístiques i trets genètics. Cavalli-Sforza va suggerir que l’anàlisi de les dades genètiques podria permetre traçar un arbre dels llinatges de les poblacions humanes i començar a reconèixer l’existència de paral·lelismes entre la classificació genètica i la classificació de les llengües i altres trets culturals.
Les conclusions dels treballs de Cavalli-Sforza i dels seus col·laboradors van originar controvèrsies que van resultar molt fructíferes per a l’avanç dels diferents àmbits científics concernits: deriven les llengües actuals d’una única llengua?, tenen les llengües africanes característiques més arcaiques que la resta?, recolzen les diferències genètiques la singularitat lingüística de llengües com el basc? Com tots els treballs sòlids i singulars, van servir també d’esperó per a moltes investigacions interdisciplinars.
Els treballs del grup de Cavalli-Sforza es fonamentaven en l’estudi de gens i tenien com a objectiu poblacions i famílies lingüístiques de continents sencers o bé de tot el món. Investigacions posteriors van començar a indagar si existia també algun paral·lelisme entre la diversitat genètica i lingüística a menor escala. En l’àmbit europeu s’han realitzat estudis fonamentalment en els dominis de les llengües germàniques i romàniques, molts d’ells recorrent a un indicador menys precís que els gens i que havia estat aprofitat en el estudis de poblacions des de feia temps: els cognoms. Com a exemple, el 2015 un grup d’investigadors van identificar connexions entre la fragmentació dels regnes medievals d’Espanya, els romanços peninsulars i l’organització regional dels cognoms contemporanis.
Cognoms i poblacions
L’ús dels cognoms en els estudis genètics es remunta al segle XIX, quan George Darwin, fill de cosins germans (Charles i Emma), va estudiar la consanguinitat en poblacions rurals d’Anglaterra a partir de la coincidència de cognoms dels dos membres de la mateixa parella (l’estimació de la isonimia). En la majoria de les societats europees, els cognoms es van fer hereditaris a partir de l’Edat Mitjana, i des del segle XVIII, bona part dels estats van oficialitzar el seu ús.
Pocs anys després de l’estudi de Darwin, el seu compatriota Henry Guppy va mostrar que els cognoms (family names) es distribuïen territorialment de forma organitzada i tenien límits de difusió similars a les fronteres polítiques i naturals. Treballs posteriors van descobrir que alguns cognoms, com els originats a partir de noms de lloc (Ariza, Barceló, Orozco, Ares, etc.), traçaven un radi que marcava la mobilitat i extensió dels grups poblacionals. Els cognoms, com els gens, funcionen com a contenidors d’informació que podien ser aprofitats per indagar en la història, les vinculacions i la distribució de les poblacions.
Cognoms i dialectes
Seguint el mètode emprat en alguns d’aquests treballs, un grup interdisciplinari de lingüistes i matemàtics hem emprès l’estudi dels cognoms de diferents zones peninsulars per descobrir què ens poden dir aquests noms propis sobre les poblacions que els porten. En el nostre estudi, publicat a la revista Journal of Linguistic Geography, analitzem la distribució territorial dels cognoms d’Astúries.
A diferència de treballs previs basats en dades provincials i més parcials, la nostra investigació parteix de censos complets dels 78 municipis asturians. Aquests registres van ser filtrats de dues maneres per obtenir un conjunt més significatiu:
- Es van eliminar aquells cognoms que per la seva freqüència dificulten la descoberta de les agrupacions regionals (els més freqüents – García, Fernández, Rodríguez, etc.- i els més rars);
- A més, es va realitzar un tall temporal (cognoms de persones nascudes abans de 1960) per minimitzar la repercussió dels moviments de població a conseqüència de les migracions a les ciutats.
El conjunt resultant es va tractar amb procediments estadístics que van permetre identificar les principals regions de cognoms d’Astúries.
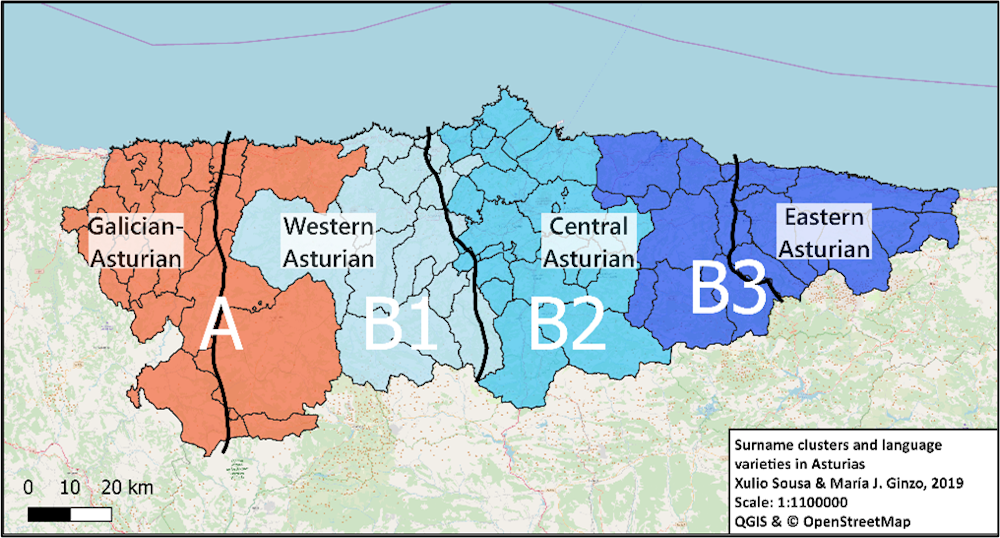
El resultat mostra 4 agrupacions compactes, separades per barreres que corren de nord a sud i que s’assemblen bastant en el seu traçat a les isoglosses que separen les varietats lingüístiques asturianes.
Així mateix, és possible reconèixer que els dos primers grans blocs de la fragmentació dels cognoms mostra coincidències evidents amb la partició del territori d’Astúries entre una àrea lingüística occidental, amb característiques compartides amb el gallec, i altres tres zones, identificades amb traços exclusius de l’asturià.
Un camp de dades a explotar
Els lingüistes interessats per la variació lingüística investiguem les dades amb la intenció de descobrir les causes que ajuden a comprendre com i per què divergeixen les llengües. L’estudi de la distribució de cognoms en una població permet obtenir informació sobre la seva mobilitat i sobre l’extensió de les relacions grupals.
Les característiques lingüístiques es difonen socialment en la interacció i, per tant, són dependents de les relacions i moviments de les comunitats, que poden ser observades a partir de la informació proporcionada pels cognoms.
Els resultats destacats en el nostre treball s’adonen que les similituds entre les dues classes de dades poden ser conseqüència de formes d’ocupació del territori del passat. Amb seguretat, la cooperació d’investigadors de diferents disciplines contribuirà a continuar explotant tot el valor informatiu d’aquesta classe tan peculiar de noms propis.
Aquest article va ser publicat originalment a The Conversation. Llegiu l’original.
